2019年10月22日中午,偶然在 freeCodeCamp 翻译协作组微信群看到 Miya 转发的一篇 Quincy 文章:What the heck is going with freeCodeCamp’s servers?
文章中开篇就声明最近一段时间 freeCodeCamp 的服务器很不稳定,工程师花费三天时间才查明问题的症结就是下面的这行代码。
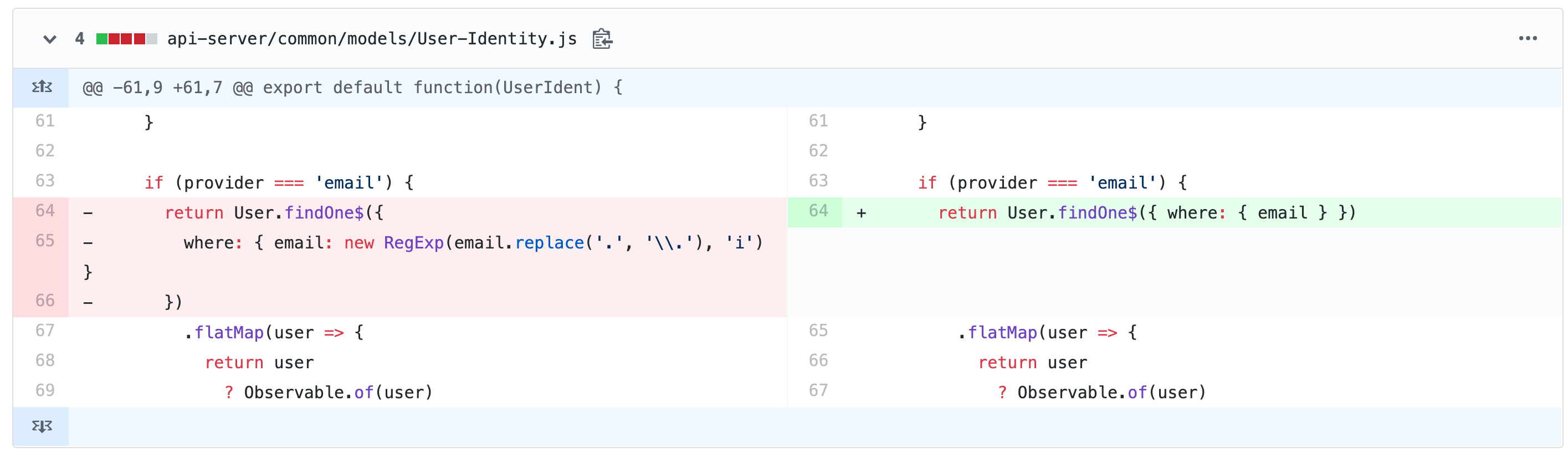
图片左边是有问题的版本,右边是修复后的版本。
要搞清楚问题的来龙去脉,我们首先需要聚焦:
这行代码到底解决了什么问题? new RegExp (email.replace('.' , '\\.' ),i)
当我第一次看到双重转义(\\)时,确实有点懵。
印象中我好像在哪里见过双重转义,但一直没搞明白在什么样的场景下需要用到双重转义。
程序员都知道.符号在正则表达式中是元符号的一种,它代表着任意单个符号,除了换行符和行结束符。
创建正则表达式有两种方式:字面量和构造函数 /pattern/attributes
new RegExp(pattern,attributes)
我们先创建一个忽略邮箱大小写的正则表示式:
var a = 'huluoyang@gmail.com' var b = 'hu.luoyang@gmail.com' var c = 'huoluoyang@gmail.com' var re = /hu.luoyang@Gmail.com/i re.test(a) re.test(b) re.test(c)
代码解释:正则中的.符号代表任意单个字符,所以能匹配变量 b 和 c ,但却不能匹配变量 a。
如果我们想让正则只能匹配变量 b ,就必须在正则中使用转义符号(\),譬如:
var a = 'huluoyang@gmail.com' var b = 'hu.luoyang@gmail.com' var c = 'huoluoyang@gmail.com' var re = /hu\.luoyang@Gmail.com/i re.test(a) re.test(b) re.test(c)
当我们想直接从字符串生成正则时,字面量此时就失效了,必须采用构造函数的方式。
此时如果字符串中包括特殊字符,譬如:.,就必须在特殊字符前使用双重转义符号(\\)。
var a = 'huluoyang@gmail.com' var b = 'hu.luoyang@gmail.com' var c = 'huoluoyang@gmail.com' var str = 'hu\\.luoyang@Gmail.com' var re = new RegExp (str,'i' )` re.test(a) // false re.test(b) // true re.test(c) // false
为什么在字符串中才需要使用双重转义,而正则中只需要使用单重转义呢? 这是因为转义符号在字符串中的作用范围是有限的。
'hu\.luoyang@gmail.com' 'hu.luoyang@gmail.com' 'hu\\.luoyang@gmail.com' 'hu\.luoyang@gmail.com'
当js引擎发现字符串中的转义符号不是在特殊符号前,它便认为此转义符号无效,因此在输出时便扔掉了。
所以要想让js引擎在输出时不扔掉转义符号,唯一的办法就是在转义符号前再添加一个转义符号,由此形成双重转义。
搞明白了双重转义的适用场景,我们也就回答了第一个问题:这行代码到底解决了什么问题?
new RegExp (email.replace('.' , '\\.' ),i)
这行代码传入一个字符串参数email,通过replace方法实现双重转义点符号,最后通过构造函数生成一个忽略邮箱大小写的正则表达式。
代码逻辑是正确的,但为何会产生性能问题呢? 我们来做个实验,看看正则和字符串在大规模数据中的查找效率到底表现如何?
首先我们需要构造一千四百万条数据:
var first_name = 'abcdefghigklmnopqsrtuvwxyzABCDEFGHIGKLMNOPQRSTUVWXYZ' var second_name = 'abcdefghigklmnopqsrtuvwxyzABCDEFGHIGKLMNOPQRSTUVWXYZ' var third_name = 'abcdefghigklmnopqsrtuvwxyzABCDEFGHIGKLMNOPQRSTUVWXYZ' var provider = ['gmail' ,'qq' ,'163' ,'126' ,'foxmail' ,'hotmail' ,'sina' ,'sohu' ,'weibo' ,'yahoo' ]var suffix = ['com' ,'cn' ,'org' ,'net' ,'one' ,'im' ,'top' ,'biz' ,'md' ,'code' ]var data = []for (var i=0 ;i<first_name.length;i++){ for (var j=0 ;j<second_name.length;j++){ for (var k=0 ;k<third_name.length;k++){ for (var u=0 ;u<provider.length;u++){ for (var h=0 ;h<suffix.length;h++){ var obj = {} obj.email = first_name[i]+second_name[j]+third_name[k]+'@' +provider[u]+'.' +suffix[h] data.push(obj) } } } } } console .log(data.length)
然后我们写一个函数来实现查找功能:
function search (source ) var result var start_time if (typeof source == 'string' ){ start_time = new Date ().getTime() result = data.find(item => }else if (source.constructor == RegExp ){ start_time = new Date ().getTime() result = data.find(item => } var end_time = new Date ().getTime() var cost_time = end_time - start_time console .log(result) console .log('time: ' + cost_time) return cost_time }
最后我们输入不同的参数来测试实验结果。
function input (source ) var total_time =0 ; for (var j=0 ;j<100 ;j++){ total_time += search(source) } console .log(total_time/100 ) } input('zzy@gmail.com' ) input(/ZZY@gmail.com/i ) input(new RegExp ('ZZY@gmail\\.com' ,'i' ))
由此可见:在js中,字符串在大规模数据中的查找效率要高于正则四五倍左右。 当然上面的结论并不一定正确,它跟具体实现息息相关。
我不清楚 Mongodb 的底层是如何实现条件查询的,如果有精通 Mongodb的大牛恰巧读到此篇文章,还望不吝赐教。
最后,附上 Quincy 的精彩文章以飨读者:https://www.freecodecamp.org/news/freecodecamp-servers-update-october-2019/